
こんにちは、 Ad Generation(以下、アドジェネ)動画リワード広告専用SDK「VAMP」開発チームのリーダーの迎 昭宏と、田島 俊英です。
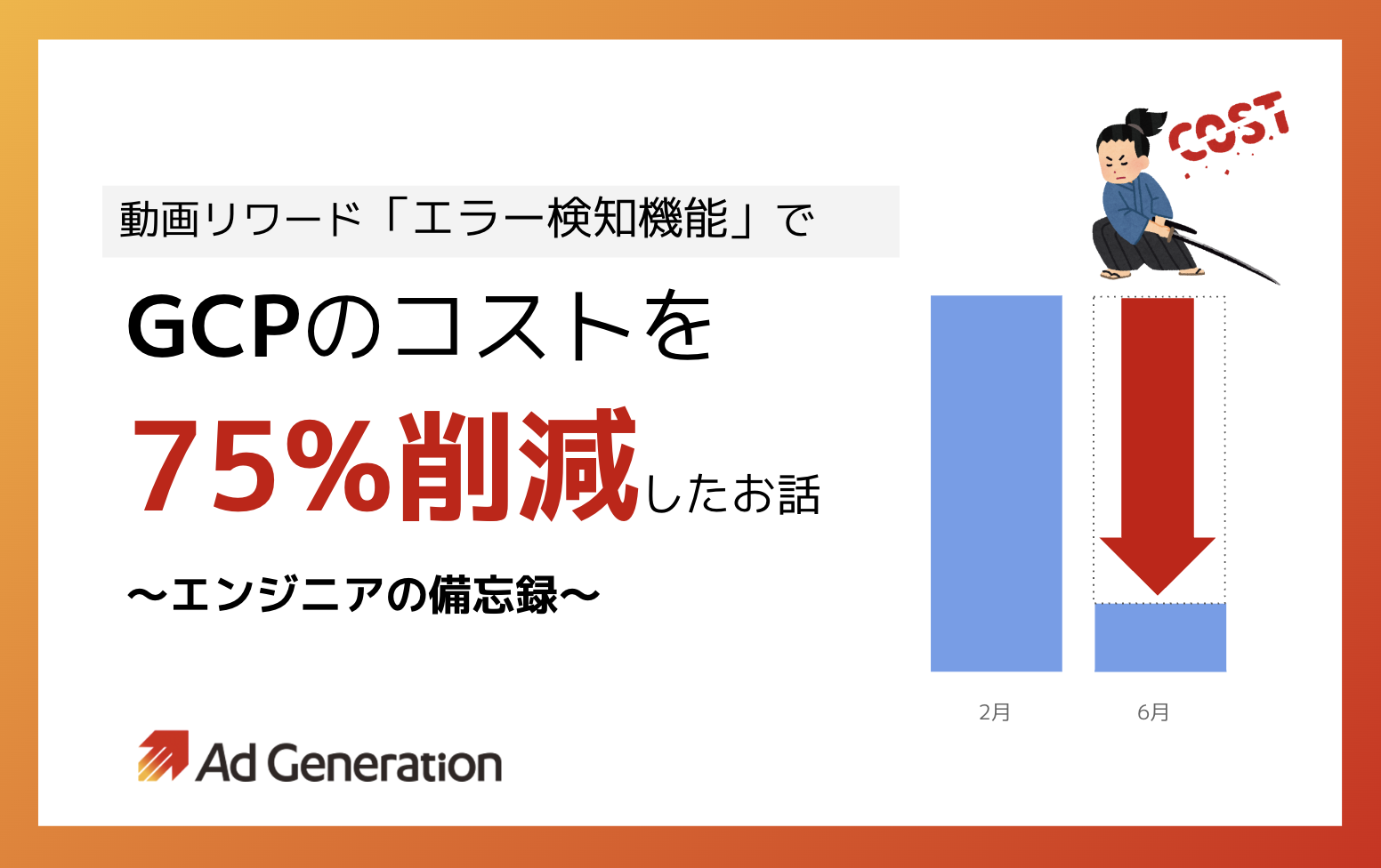
今回は、動画リワード広告専用SDK「VAMP」のエラー検知機能で、エラーログ収集に活用しているGoogle Cloud Platform(以下GCP)のコストを75%ほど削減した、というお話を備忘も兼ねて誰かのお役に立てればと思いご紹介します。
※2022/08/05編集部追記:7月実績ではピーク時から85%減を達成しました!
アドジェネ動画リワード独自のエラー検知機能とは?
アドジェネの動画リワードは、専任の担当による収益とテック面での手厚いサポート体制を強みに、モンスターストライクをはじめとする多くのアプリパブリッシャー様に採用いただいています。
導入事例:
→モンスターストライク導入事例はこちら
→導入事例をもっとみる
導入いただいているパブリッシャー様から、特にご評価いただいているのが「エラー検知機能」です。
「エラー検知機能」とは、エラーログを自動収集することで速やかな調査・対応を進めることができる機能です。アドネットワーク各社のSDKと連携し、どのアドネットワークでどの端末でエラーが発生したのか、クラウドに蓄積されたログを基にエラーの原因究明・対応を行うことができます。これにより、ユーザーからの問い合わせをもとに調査・対応を行う従来方式よりも迅速な対応を先回りで行うことが可能となります。(詳しくはこちらで解説しています)
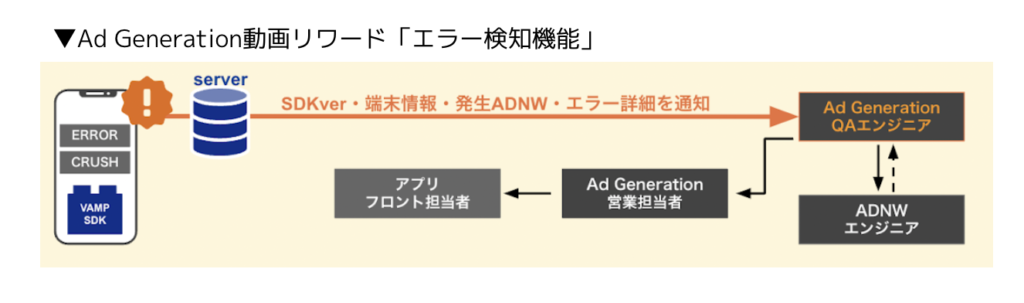
エラーログを自動収集することで速やかな調査・対応を進めることができる独自機能
ある日、ログの急増により早急な対応が必要に
「エラー検知機能」は、Google Cloud Platform(GCP)のクラウドサービスを使って構築した収集・分析システムによってご提供しています。
主に使っているのは「Cloud Functions」、「Cloud Logging」、「BigQuery」などのサービスで、利用量に応じた従量制となっているこれらをVAMP開発チームで使える予算内で運用しています。
GCPの費用はさまざまな要因(サービスを利用するメディアが増える、為替の影響など)で毎月上下するのですが、おかげさまで多くのアプリに導入いただいたことで毎月右肩上がりで増えていく費用に嬉しい悲鳴をあげつつも、これまで安定的に予算内での運用を続けることができておりました。
しかし2022年2月のある日、予想外の問題が発生しました。突発的なログの急上昇が発生し、日予算が2倍以上に跳ね上がったのです。
原因は、3連休の初日で通常よりも多くのトラフィックが発生したことと、パブリッシャー様による新規アプリがリリースされた影響で想定を超えたログの急増が起こりました。
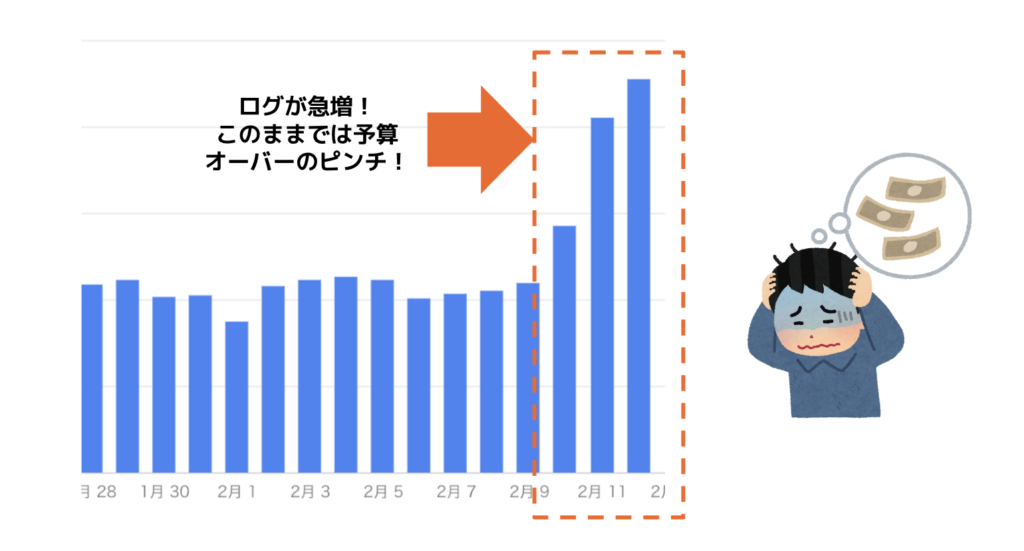
このままでは予算をオーバーしてしまうため、「エラー検知機能」を安定稼働させつつも、早急にコストを抑える対応を行わなければなりません。
ということで、以下のステップで対応を進めて行くことにしました。

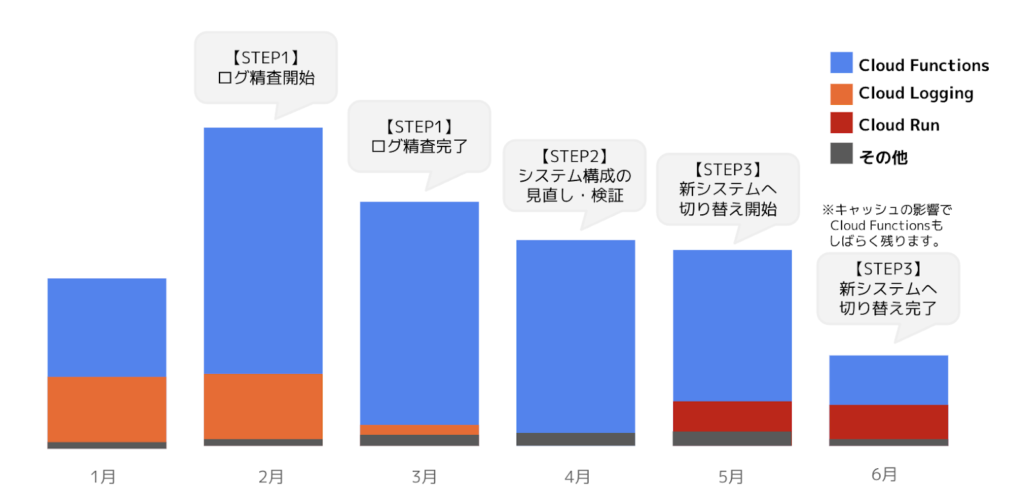
【STEP1】ログの精査
まず第1ステップとして、溜まっているログの詳細を改めて精査してみました。
「Cloud Functions」でトリガーを設定し「Cloud Logging」へログを渡していますが、保存している項目は、本当に全て保存する必要があるのか?不要なログが減ればその分費用も減らせるのでは?ということで、まずは「Cloud Functions」側で記録しなくても良い項目を洗い出して、不要なログをフィルタリングする作業を行いました。
大きな費用削減効果は見込めないかもしれませんが、ログのボリュームに比例してコストがかかってくるので、丁寧に精査して削りました。
ちなみに、「Cloud Functions」のデフォルト設定では、詳細なシステムデバッグログが大量に書き込まれていました。エラー検知機能において、これらのログは特に不要であることがわかったので、ログルータでフィルタリングして停止しました。
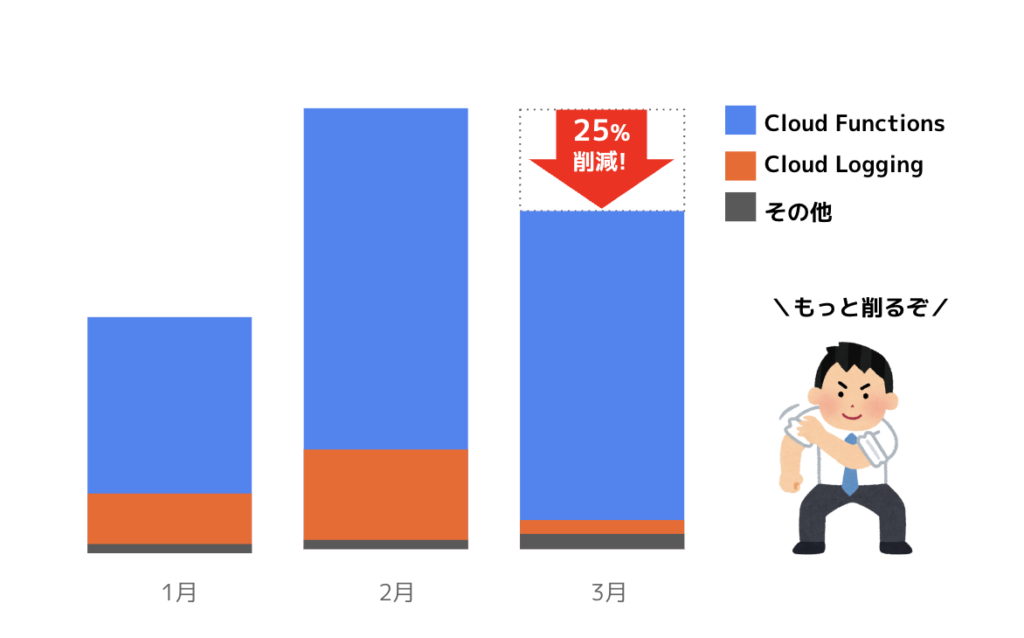
結果、この対応をするだけで、3月の「Cloud Logging」の費用を75%も削減することに成功しました。
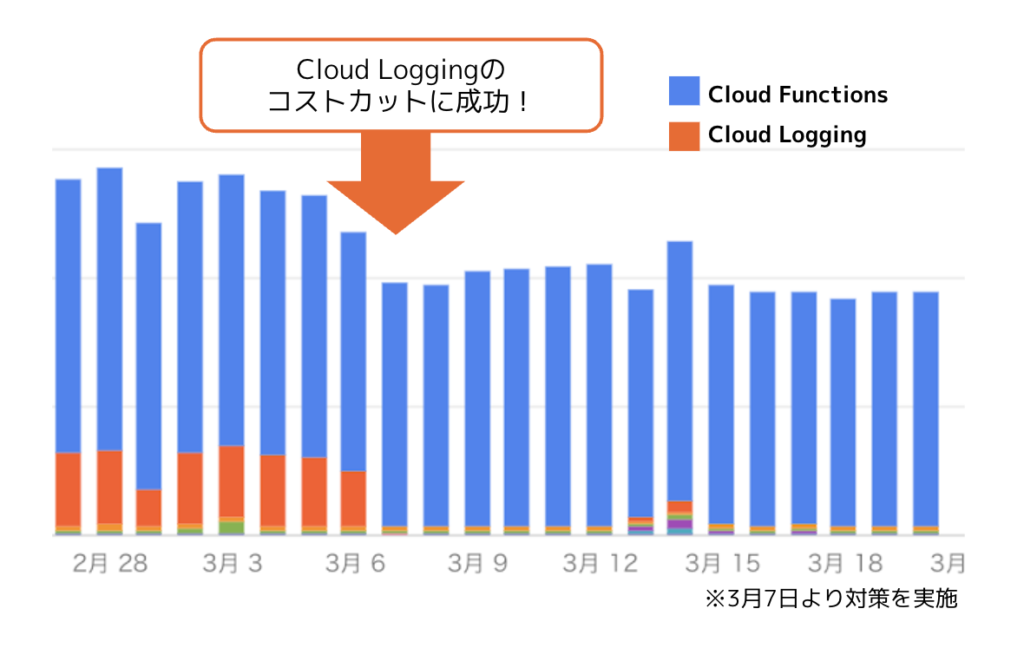
日別のコスト推移
ただ、GCP全体のコストで見るとまだまだ削減の余地がありそうだなということで、次のステップへと移ります。
【STEP2】システム構成の見直し・検証
2019年にGCPで開発・構築したエラー検知機能を本格稼働させてから、3年以上が経過しました。
その間にGCP自体の機能のアップデートや、新たなシステムがリリースされるなど、GCPが進化していたことから、最新機能を使ったシステムの最適化でコスト削減の可能性を探ります。
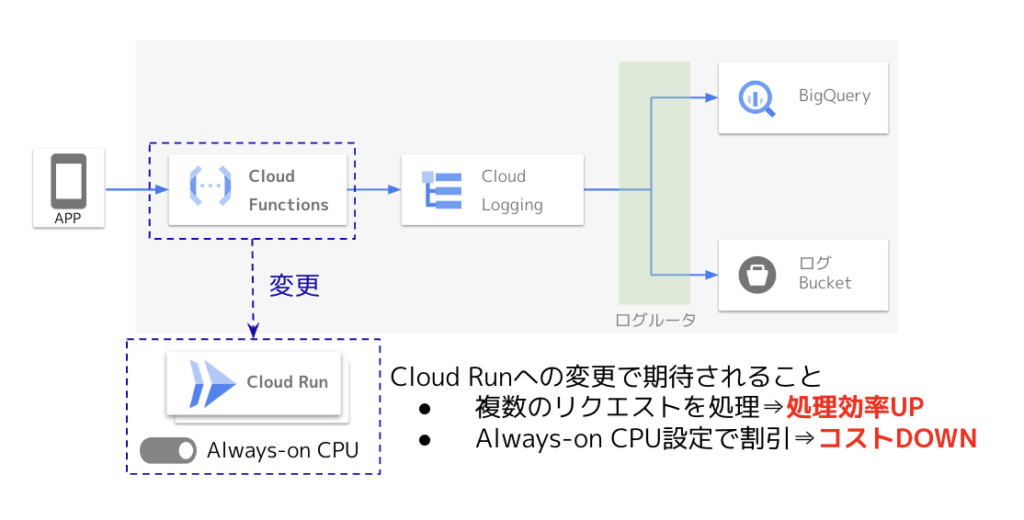
①「Cloud Functions」から「Cloud Run」へ
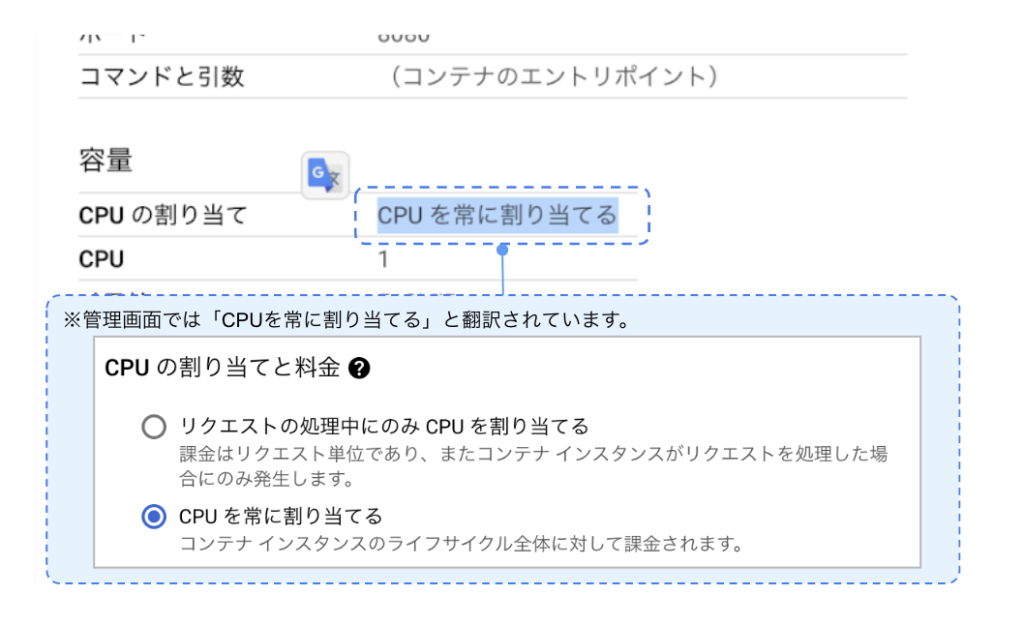
2021年9月 Google Cloud Blogにて紹介された「新しい CPU 割り当てコントロールにより Cloud Run 上でさらに多様なワークロードを実行」という記事を参考に、これまで使っていた「Cloud Functions」を「Cloud Run」へ切り替えた上で、設定画面で「CPU 常時割り当て(Always-on CPU)」を有効にする方法を試すことにしました。
「Cloud Functions」は1リクエストを1つのインスタンスで処理するのに対し、「Cloud Run」は複数のリクエストを1つのインスタンスで処理することができます。
さらに、「Always-on CPU」を有効化すると、リクエスト処理以外のCloud RunコンテナインスタンスにもCPUを割り当てられるので、処理の高速化を期待できます。また、後に記載する負荷試験の結果などから、今回のユースケースではコストの削減が期待できることが分かりました。
なお、他に「AppEngine」、「Pub/Sub」、「Dataflow」などの構成も検討しましたが、実際に見積もってみた結果、コスト削減が見込めず採用を見送りました。
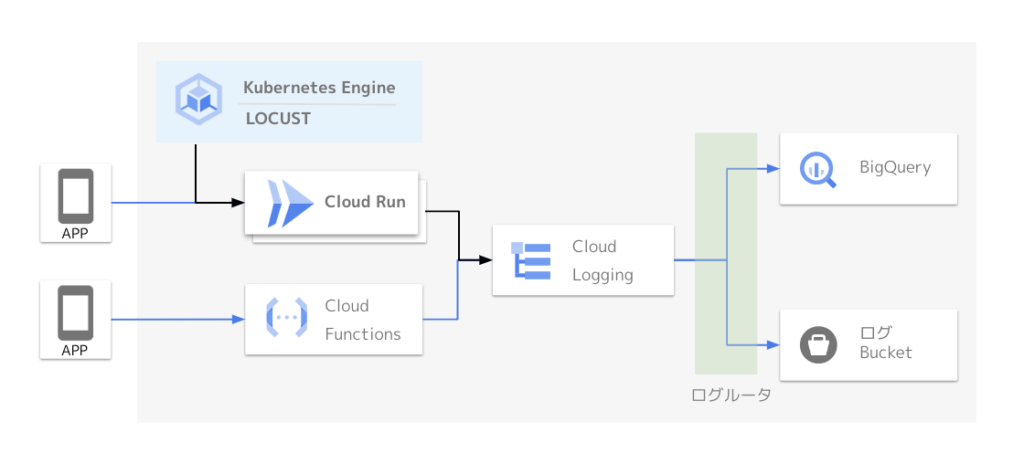
②テスト環境の準備
「Cloud Run」をいきなり本番環境に実戦投入することはできないので、まずは「Cloud Run」のテスト環境を作ってLOCUST(負荷試験ツール)を利用した負荷テストを実施します。
(GCP公式チュートリアル参考)
③負荷テスト実施
「Cloud Functions」へのリクエスト数の実績から、負荷をかけるリクエスト数(秒間の平均値と最大値)を算出していきます。実績値と同じ条件での負荷テストを行ったうえで、秒間最大リクエスト数の2倍の負荷を与えても問題が起きないのかについても念の為確認しました。
▼テスト項目
- CPU:CPU負荷が高まるとインスタンスがスケールするか?
- メモリ:大量アクセスさせてもメモリ不足・メモリーリークを起こさないか?
- レイテンシ:稼働中の「Cloud Functions」と同程度のレイテンシであるか?
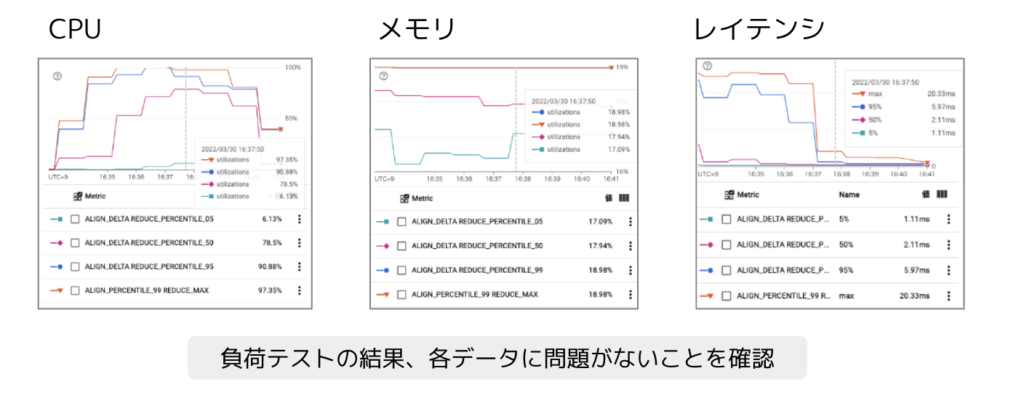
負荷テストに関しては問題なさそうなので次のステップへ進みます。
④テスト結果から費用を試算
「Cloud Run」は「処理時間」と「リクエスト回数」に応じた従量課金となっています。
テスト実績から想定される「処理時間」で、2月の実績値をもとに見積もってみたところ、「Cloud Function」から「Cloud Run」への切り替えにより約70%も費用を削減することができそうです。
これに加えて、負荷試験の結果から「処理時間」にかかるコストよりも「リクエスト回数」にかかるコストの比重が大きいことが分かりました。処理していない時間もCPU を常時割り当てるオプション「Always-on CPU」を管理画面で設定することで、リクエスト毎の課金がなくなりさらなる料金の割引が期待できます。
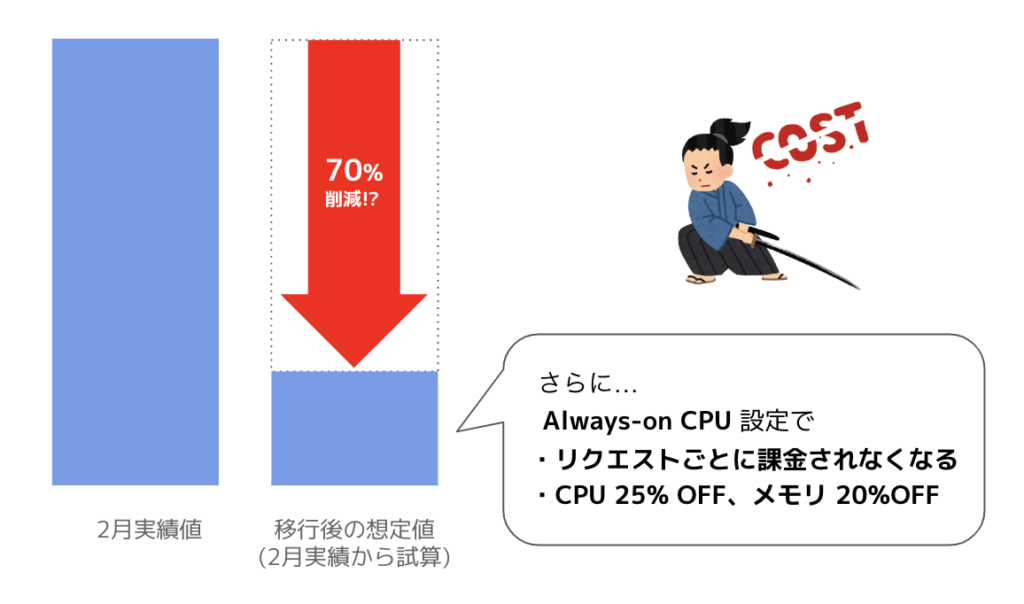
Cloud Run への移行で想定される費用
※「Always-on CPU」は、日本語の管理画面では「CPUを常に割り当てる」と表示されています。
⑤「Cloud Run」システム構成の最適化
負荷テストは、「Cloud Run」のデフォルトのシステム環境のまま実施していたのですが、ここをさらに最適化することでさらにコストパフォーマンスが上がるのではないかと考え、いくつかの方法を探ることにしました。
1.システム環境の初期構成
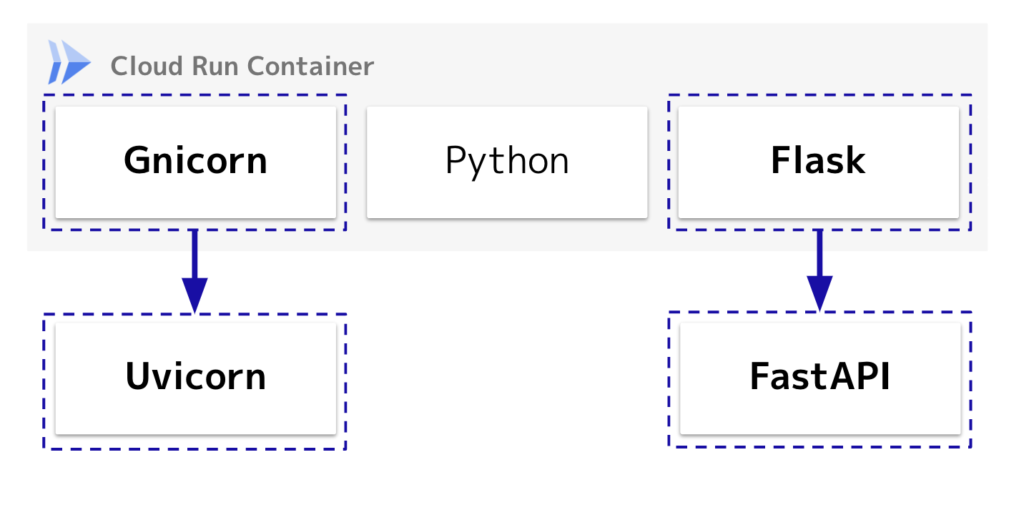
「Cloud Run」のデフォルトのコンテナ実行環境は、Gunicorn + Python + Flaskの構成となっています。実際に稼働させてみるといくつかの課題がみえてきました。
▼Flask版で感じた課題
- Python製なのでWebサーバー自体の速度がでない
- 非同期処理が作成しにくく、ログAPIの実行(100〜200ms)を待たなければいけない
- 安定してリクエストを返すために最小インスタンスを大き目に設定しなければいけない
色々と情報収集したところ、ソフトウェアスタックを変更することで改善できそうでしたので、試していきます。
2.Gunicorn → Uvicorn、Flask → FastAPIへ変更
この構成に変更をすることで、安定稼働と費用削減の両立する手応えが得られました。
3.FastAPIからGo+Echoへの変更を試すも問題発生で保留
FastAPIによって安定的にコストを抑えた運用が実現できそうではあるものの、理想系まではあと一歩という感触だったので、さらなる改善を追求してGo+Echoの構成も試してみました。
▼FastAPI版で感じた課題
- スケールアウトする時にインスタンスの生成(コールドスタート)に数秒かかってしまう
- 安定してリクエストを返すために最小インスタンスを適切な値に設定しなければならない
- リクエスト数の増減に合わせて最小インスタンスの設定を変更する必要があるので手間がかかる
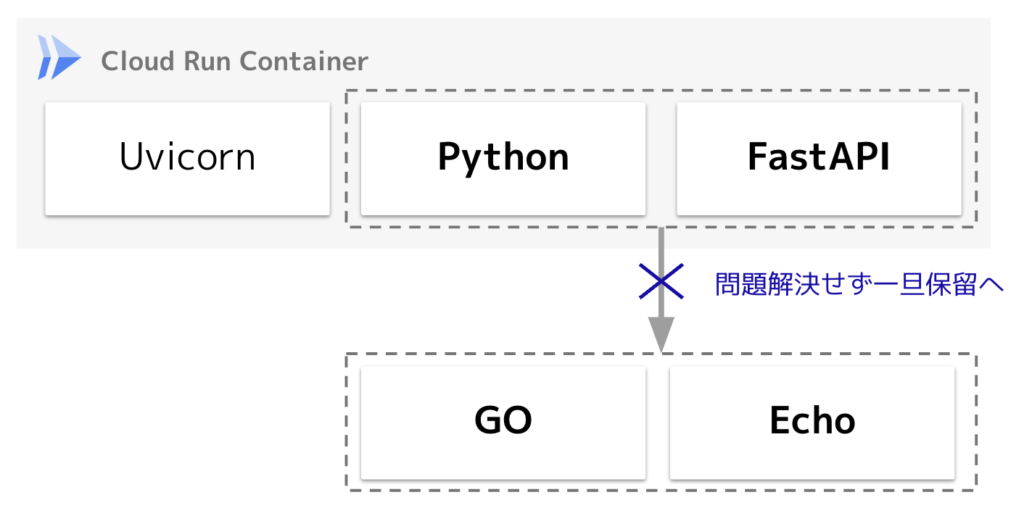
しかし検証の結果、負荷が高まった時にネットワーク起因と思われるエラーが頻発してしまい試行錯誤するも解消せず、改善に時間をかけることができなかったのでタイムオーバーとなりこちらのシステム導入は断念しました。
【STEP3】新システムへの切り替え
テスト環境にて試行錯誤をした結果、「Cloud Run」のコンテナ実行環境をUvicorn +Python+FastAPIへ変更するのが最善策であると判断し、5月から段階的にシステムの切り替えを行い、6月には100%切り替えが完了しました。
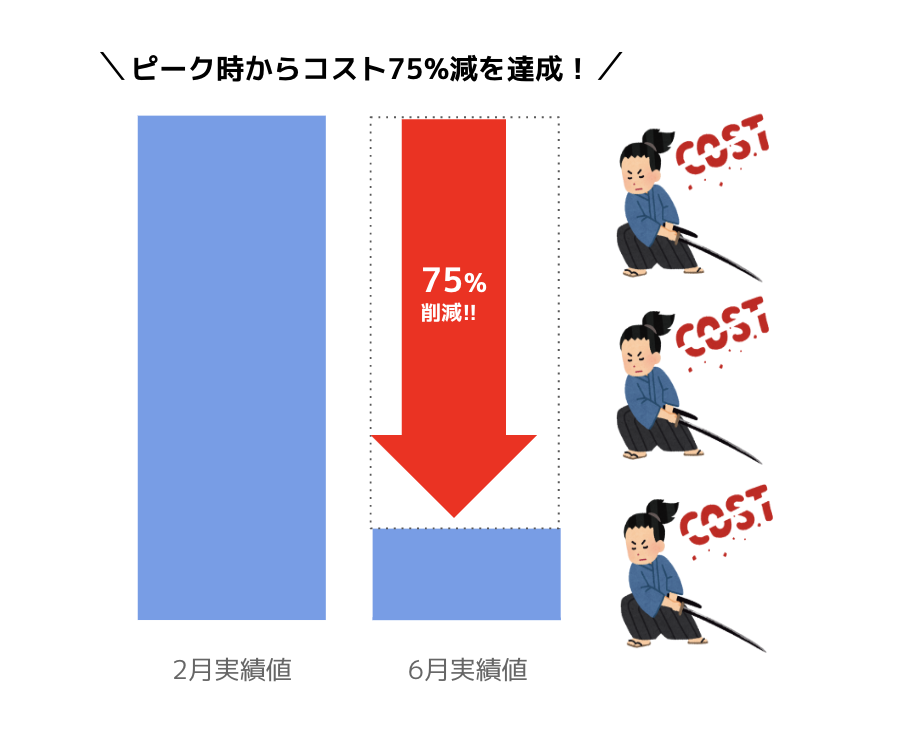
【結果】コスト75%削減に成功!
完全に切り替えが完了した6月と、突発的な需要で急騰した2月の実績値を比べると、GCP全体の費用を75%も削減することができました。
※2022/08/05編集部追記:7月実績ではピーク時から85%減を達成しました!
まとめ・感想
今回の対応を時系列でまとめると以下の通り。
- 2〜3月:ログの精査・削減
- 4月:新システムへの切り替え検討・検証
- 5月:新システムを一部環境に導入
- 6月:新システムへの完全切り替え
結果、ピーク時と比較して75%ものコスト削減に成功しました。
今回は不測の事態が発生したことによって機能を改善すべきであったことに気づかされました。
一度システムを稼働させて安定運用していると、触らぬ神に祟りなしで、何もしないでおこうといった心理が働いてしまいがちです。
クラウドサービスの提供側はシステムを進化させていくので、利用者側の我々もアップデート情報や新機能の発表を定期的にキャッチアップすることの重要性を強く感じました。
今回の対応によって得られた知見を、パブリッシャーの皆様にもサービスとして還元していけるよう、我々もアップデートし続けていきたいと思います。
アドジェネのアップデート情報:Cookieレスでも収益性を維持する「Hyper ID」対応
アドジェネでは、ポストCookie時代の次世代型ターゲティング広告配信ソリューション「Hyper ID」に対応しております。
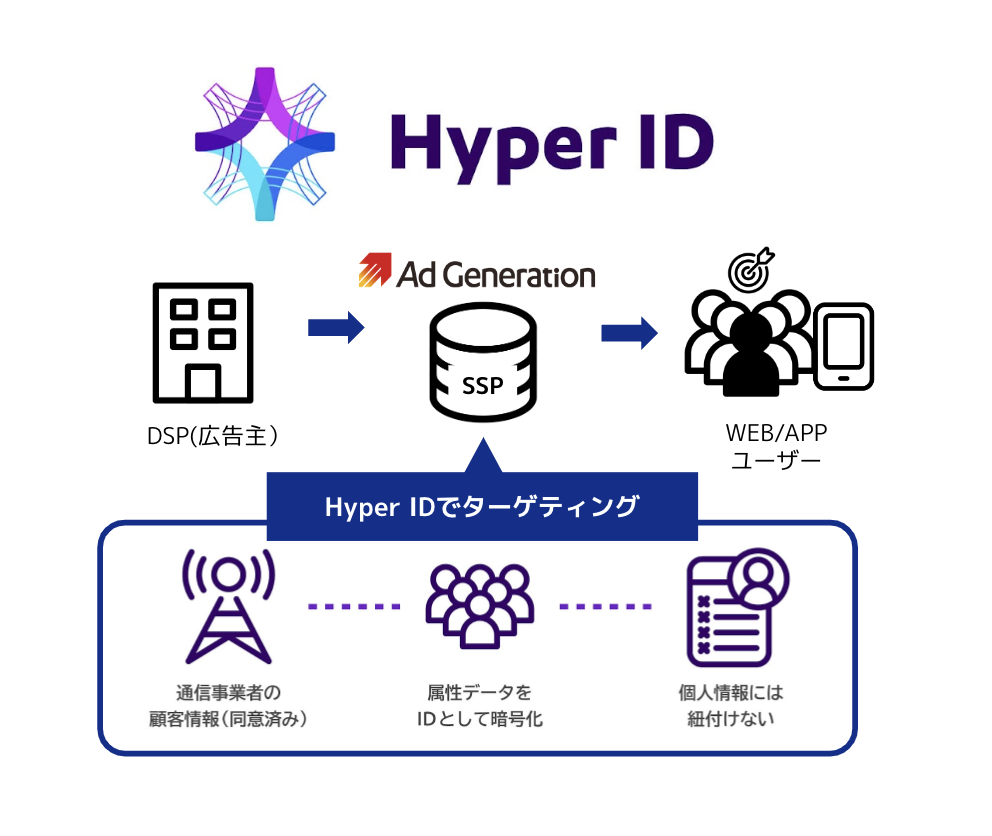
キャリアデータを活用した、アドジェネだけの唯一無二のテクノロジーで、Cookieレスにおいても高パフォーマンスなターゲティング広告が配信可能です。
ユーザーがサイトやアプリにアクセスする際に割り振られるIPアドレスから、広告配信専用の「Hyper ID」を取得し、ユーザー属性(許諾済み)を利用したターゲティング配信を実現します。
「代替ID」と呼ばれるいくつかのCookieに代わるIDソリューションが注目されている中で、「Hyper ID」はログイン状態の有無に関わらずキャリアデータを基にした正確なターゲティングが可能で、プライバシーファーストな設計による安全性も兼ね備えております。WEBサイトにおいては、Prebid.jsのヘッダービディング設定にてビッダーにAd Generationを追加いただくだけで対応が完了となり、アプリの場合は最新のSDKを導入するだけでご利用いただくことができます。(特に手続きなどは不要です)
今後、iOSだけでなくAndroidにおいてもリターゲティング広告の配信ができなくなることで収益性の低下を懸念されているパブリッシャー様や、Cookieレスでのターゲティング配信にご興味のある広告主様・代理店様は、詳細をご案内致しておりますのでお問い合わせください!
▼「Hyper ID」関連リリースはこちら:
・Supershipの「ScaleOut DSP」、独自開発の広告配信用IDでCookieレスのターゲティング配信を提供開始~プライバシーに配慮した「Hyper IDターゲティング」で、ユーザーのライフスタイルに関連した高精度の広告配信が可能に~
・Supershipの「Ad Generation」、キャリアデータを活用したCookieレスで高精度なターゲティングを実現する「Hyper ID」でマイクロアドの「UNIVERSE Ads」と連携
Related
関連記事
-

テクノロジー
アドジェネのサービス品質保持のために、QAチームでGASを活用したお話〜エンジニアの備忘録〜
- Ad Generation
- エンジニア
- 動画リワード
-

コラム
『GANMA!』のケーススタディ 動画リワードでAd Generationを活用
- Ad Generation
- 動画リワード
-

テクノロジー
パブリッシャーにも、ユーザーにもメリットを!エラー検知機能とCOPPA対応(アドジェネ動画リワード広告 v3.1アップデート)
- Ad Generation
- SSP
- エンジニア
- 動画リワード
-

テクノロジー
フリークエンシーキャップ、視聴キャンセルなど…アドジェネの動画リワード広告で新規に追加された4つの新機能をご紹介!
- Ad Generation
- SSP
- エンジニア
- 動画リワード
-
テクノロジー
中の人がAd Generation動画リワード広告のオススメ実装方法をアプリのタイプ別に解説!
- Ad Generation
- SSP
- アプリマーケティング
- エンジニア
- 動画リワード
-

テクノロジー
Quality Assurance(QA)チームによる品質管理の取り組み(アドテクセンター通信)
- Ad Generation
- SSP
- エンジニア
- 動画リワード
Most Popular
人気記事



Hot Topic
おすすめ記事
-

プロダクト
オンオフデータをシームレスに連携!店舗型リテールメディア「Supership Touch Gift(タッチギフト)」とは?
- 1st Partyデータ活用
- OMO
- Supership Touch Gift
- リテールメディア
-

セミナーレポート
minne byGMOペパボが実践:商品広告を活用した「ECサイトのリテールメディア化」で何が起きた?成功の秘訣とその成果 〜イーコマースフェア 東京 2024セミナーレポート
- S4Ads
-

セミナーレポート
【2023最新版】ゲームアプリ広告収益化のベストプラクティス(Ad Generation講演レポート@ゲームビジネスカンファレンス2023)
- Ad Generation
- SSP
- 動画リワード